After I spent a few days on an autoregressive model, I want to switch my focus on GANs for the coming days. Today I worked on DCGAN [1] which is GANs that uses a deconvolution network as a generator and a convolution network as a discriminator.
Although the use of deconvolutional layers may sound straightforward, I still like some ideas of DCGAN’s architectures:
- It does not use any max-pool at all and uses a strided convolutional layers to down-sampling instead. The use of multiple convolutional layers for down-sampling was proposed by [2].
- It uses a deconvolutional layer as part of the generator by slowly double the number of channels until it reaches the desired image dimensions.
- This is a subtle idea. It uses LeakyReLU instead of ReLU.
I modified my Vanilla GAN by replacing the generator and discriminator with conv and deconv layers.
We randomly select 16 random vectors with a dimension of 64 drawn from a normal distribution. Each column represents one unique vector. Each row represents the number of epochs.
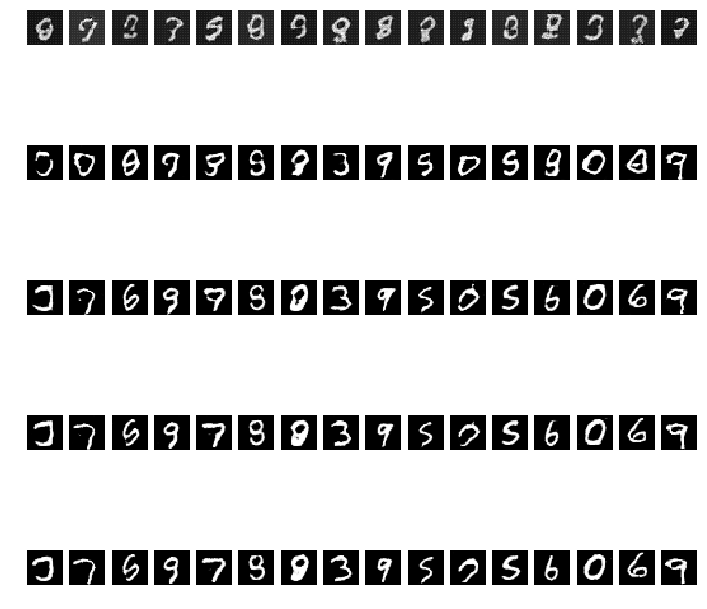
Sampled digits generated by the generator. Each row represents the number of epoch. From top to bottom: epoch 10, 50, 100, 150, and 200. We can see that the more epochs, the better image quality.
DCGAN generates much better image quality than Vanilla GAN. Hence, convolutional and deconvolutional layers give representation and classification power to the models.
Loss Plot
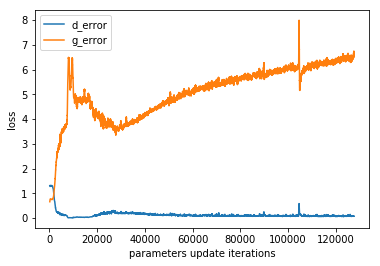
To be honest, the loss does not look good to me. I expected the loss from the generator slowly decays overtimes but that is not the case here. It seems that the discriminator performs a binary classification extremely well. This could be bad for the generator since it will never receive a positive signal, but only negative signals. The better training strategy will be explored in my future study.
Closing
DCGAN is a solid work because the generated images are significantly better than Vanilla GANs. This simple model architecture is more practical and will have a long-lasting impact than a sophisticated and complex model.
References:
[1] DCGAN original paper
[2] Striving For Simplicity: The All Convolutional Net (ICLR’15)


You must be logged in to post a comment.