This is one of the early paper on generative modeling. This work was on arXiv since Oct 2013 before the reparameterization trick has been popularized [2, 3]. It is interesting to look back and see the challenge of training the model with stochastic layers.
Model Architecture
Deep Autoregressive Network (DARN) is a flexible deep generative model with the following architecture features: First, its stochastic layer is stackable. This improves representational power. Second, the deterministic layers can be inserted between the stochastic layers to add complexity to the model. Third, the generative model such as NADE and EoNADE can be used instead of the simple linear autoregressive. This also improves the representational power.
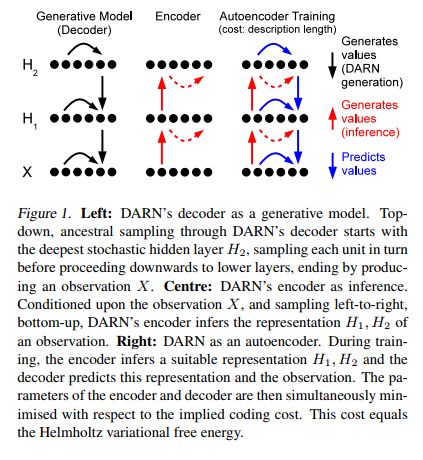
The main difference from VAE [2] is that the hidden units are binary vectors (which is similar to the restricted Boltzmann machine). VAE requires a continuous vector as hidden units unless we approximate the discrete units with Gumbel-Softmax.
DARN does not assume any form of distribution on its prior 

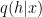
Sampling
Since DARN is an autoregressive model, it needs to sample one value at a time, from top hidden layer all the way down to the observed layer.
Minimum Description Length
This is my favorite section of this paper. There is a strong connection between the information theory and variational lowerbound. In EM algorithm, we use Jensen’s inequality to derive the smooth function that acts as a lowerbound of the log likelihood. Some scholars refer this lowerbound as an Evidence Lowerbound (ELBO).
This lowerbound can be derived from information theory perspective. From the Shannon’s theory, the description length is:

If 

The main idea is simple. The less predictable event requires more bits to encode. The shorter bits is better because we will transport fewer bits over the wire. Hence, we want to minimize the description length of the following message
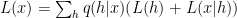
The

Finally, the entire description length or Helmholtz variational free energy is:

This is formula is exactly the same as the ELBO when
Learning
The variational free energy formula (1) is intractable because it requires summation over all
The expectation term is approximated by sampling 
Closing
DARN is one of the early paper that use the stochastic layers as part of its model. Optimization through these layers posed a few challenges such as high variances from the Monte Carlo approximation.
References:
[1] Gregor, Karol, et al. “Deep autoregressive networks.” arXiv preprint arXiv:1310.8499 (2013).
[2] Kingma, Diederik P., and Max Welling. “Auto-encoding variational bayes.” arXiv preprint arXiv:1312.6114 (2013).
[3] Rezende, Danilo Jimenez, Shakir Mohamed, and Daan Wierstra. “Stochastic backpropagation and approximate inference in deep generative models.” arXiv preprint arXiv:1401.4082 (2014).
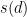 where d is a document that will yield a high score for a relevant document but low scores for non-relevant documents.
where d is a document that will yield a high score for a relevant document but low scores for non-relevant documents.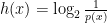
![H(X) = -\sum_x p(x) \log_2 p(x) = E[- \log_2 p(x) ]](https://s0.wp.com/latex.php?latex=H%28X%29+%3D+-%5Csum_x+p%28x%29+%5Clog_2+p%28x%29+%C2%A0%3D+E%5B-+%5Clog_2+p%28x%29+%5D&bg=ffffff&fg=000&s=0&c=20201002)
![KL(P||Q) = \sum_x p(x) \log_2 \frac{p(x)}{q(x)} = E[\log_2 \frac{p(x)}{q(x)}]](https://s0.wp.com/latex.php?latex=KL%28P%7C%7CQ%29+%3D+%5Csum_x+p%28x%29+%5Clog_2+%5Cfrac%7Bp%28x%29%7D%7Bq%28x%29%7D+%3D+E%5B%5Clog_2+%5Cfrac%7Bp%28x%29%7D%7Bq%28x%29%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)







You must be logged in to post a comment.