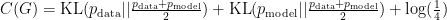This paper uses GANs framework to combine generative and discriminative information retrieval model. It shows a promising result on web search, item recommendations, and Q/A tasks.
Typically, many relevant models are classified into 2 types:
- Generative retrieval model
-
- It generates a document given a query and possibly relevant score. The model is
 .
.
- Discriminative retrieval model
-
- It computes a relevance score for the given query and document pair. The model is
 .
.
The generative model tried to find a connection between document and query. On the other hand, the discriminative model attempts to model the interaction between query and document based on relevance scores.
Both models have their shortcoming. Many generative models require a predefined data generating story. The wrong assumption will lead to the poor performance. The generative model is usually trying to fit the data to its model without external guidance. Meanwhile, the discriminative model requires a lot of labeled data to be effective, especially for a deep neural network model.
By train both models using GANs framework, it is now possible to solve their shortcoming. The generative model is now adaptive because the discriminator will reward the generative model when it can create or select good samples. This adaptive guidance from the discriminator is unique in GANs framework and will help the generator learns to pick good samples from the data distribution. At the same time, the discriminator can receive even more training data from the generative model. This is similar to semi-supervised learning where unlabeled data are utilized. Adversarial training allows us to improve both generative and discriminative models via jointly learning through the
Adversarial training allows us to improve both generative and discriminative models via jointly learning through the minimax training. The traditional training based on maximum likelihood does not have principle way to allow both models to give each other feedbacks.
The paper seems to be promising and their results on 3 information retrieval tasks are really good. But I notice that their training procedure requires pretraining. This made me wonder if pre-training is part of the performance boost during testing. I don’t find the part in the paper that explains the benefit of pretraining in their settings.
The discriminative model is straight forward. It is a sigmoid function. The discriminator basically gives a high probability when the given document-query pair is relevant. The generative model is more interesting. In the standard GANs, the generator will create a sample from a simple distribution, but IRGAN does not generate a new document-query pair. Instead, the author chose to let the generator select the sample from the document pool. In my opinion, this approach is simpler than creating a new data because the sample is realistic. Also, IRGAN cares about finding a function to compute a relevance score so it is unnecessary to generate a completely new data.
However, the cost function for the generator is an expectation over all documents in the corpus. The Monte Carlo approximation will have a high variance. Thus, they use policy gradient to reduce the variance so that the model can learn a useful representation. Although  is a discrete distribution, the backprop is applicable because we pre-sample all documents from beforehand. Thus, eq. 5 is differentiable. The extra care may need in order to reduce variance further. They use an advantage function. (Please look at the reference on Reinforcement Learning [2]).
is a discrete distribution, the backprop is applicable because we pre-sample all documents from beforehand. Thus, eq. 5 is differentiable. The extra care may need in order to reduce variance further. They use an advantage function. (Please look at the reference on Reinforcement Learning [2]).
Generating positive and negative samples are still confusing in this paper. It seems to be application specific. The author mentioned about using softmax with temperature hyper-parameter to put more or less focus on top documents. My guess is when we put less focus on top documents, the generator has more chance to pick up more negative samples. After I read the paper again, it seems that all samples selected by the generator model are negative samples. This part remains unclear and I need to ask the author for more details.
In conclusion, I like this paper because it tried to combine generative and discriminative retrieval models via GANs framework. I would not be appreciated if they simply applied the IR task to GANs blindly. Instead, they explained their motivation and discussed the advantage of jointly train both models. It seems adversarial training is useful for IR tasks as well.
References:
[1] Jun Wang, Lantao Yu, Weinan Zhang, Yu Gong, Yinghui Xu, Benyou Wang, Peng Zhang, and Dell Zhang. 2017. IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models. In Proceedings of SIGIR’17, Shinjuku, Tokyo, Japan, August 7-11, 2017, 10 pages.
[2] Richard S Sutton, David A McAllester, Satinder P Singh, Yishay Mansour, and others. 1999. Policy Gradient Methods for Reinforcement Learning with Function Approximation. In NIPS.
[3] IRGAN code (http://lantaoyu.com/publications/IRGAN)
 that approximates
that approximates 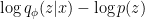 . The expectation of this term w.r.t $latex q_{\phi}(z|x)$ is in fact a KL-divergence term. Since the authors prove that the optimal
. The expectation of this term w.r.t $latex q_{\phi}(z|x)$ is in fact a KL-divergence term. Since the authors prove that the optimal  , the ELBO becomes:
, the ELBO becomes:![E_{p_{D(x)}}E_{q_{\phi}(z|x)}[-T^*(x,z) + \log p_{\theta}(x|z)]](https://s0.wp.com/latex.php?latex=E_%7Bp_%7BD%28x%29%7D%7DE_%7Bq_%7B%5Cphi%7D%28z%7Cx%29%7D%5B-T%5E%2A%28x%2Cz%29+%2B+%5Clog+p_%7B%5Ctheta%7D%28x%7Cz%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
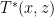 , the discriminator needs to learn to distinguish between a sample from a prior
, the discriminator needs to learn to distinguish between a sample from a prior  and the current inference model
and the current inference model  . Thus, the objective function for the discriminator is setup as:
. Thus, the objective function for the discriminator is setup as: (1)
(1)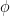 can be problematic because the solution of this function depends on
can be problematic because the solution of this function depends on  . But the author shows that the expectation of gradient of
. But the author shows that the expectation of gradient of  .
.![E_{p_{D(x)}}E_{\epsilon}[-T^*(x, z_{\phi}(x, \epsilon) + \log p_{\theta}(x|z_{\phi}(x, \epsilon))]](https://s0.wp.com/latex.php?latex=E_%7Bp_%7BD%28x%29%7D%7DE_%7B%5Cepsilon%7D%5B-T%5E%2A%28x%2C+z_%7B%5Cphi%7D%28x%2C+%5Cepsilon%29+%2B+%5Clog+p_%7B%5Ctheta%7D%28x%7Cz_%7B%5Cphi%7D%28x%2C+%5Cepsilon%29%29%5D&bg=ffffff&fg=000&s=0&c=20201002) (2)
(2) close to optimal while jointly optimizes eq. (2).
close to optimal while jointly optimizes eq. (2).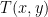 to be sufficiently close to the optimal. Basically, the KL term in ELBO is replaced by
to be sufficiently close to the optimal. Basically, the KL term in ELBO is replaced by 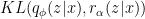 where
where 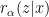 is an auxiliary distribution which could be a Gaussian distribution.
is an auxiliary distribution which could be a Gaussian distribution. and non-target word (negative samples) given a context vector
and non-target word (negative samples) given a context vector 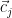 . This loss wants the model to distinguish a positive word (which related to the given context) from negative sampled words.
. This loss wants the model to distinguish a positive word (which related to the given context) from negative sampled words. . Thus, LDA2vec attempts to capture both document-wide relationship and local interaction between words within its context window.
. Thus, LDA2vec attempts to capture both document-wide relationship and local interaction between words within its context window.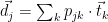 where
where  is a probability of document j will be a topic k. Finally, the interpretability comes from a sparsity of topic assignment vector,
is a probability of document j will be a topic k. Finally, the interpretability comes from a sparsity of topic assignment vector,  . One way to enforce sparsity is to design the loss function as:
. One way to enforce sparsity is to design the loss function as:
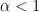 , we encourage a topic assignment probability to put more mass on a small set of topics.
, we encourage a topic assignment probability to put more mass on a small set of topics.![J^{(D)}(\theta^{(D)}, \theta^{(G)}) = -\frac{1}{2}E_{x \sim p_{\text{data}}}[\log D(x)] - \frac{1}{2}E_z[\log(1 - D(G(z)))]](https://s0.wp.com/latex.php?latex=J%5E%7B%28D%29%7D%28%5Ctheta%5E%7B%28D%29%7D%2C+%5Ctheta%5E%7B%28G%29%7D%29+%3D+-%5Cfrac%7B1%7D%7B2%7DE_%7Bx+%5Csim+p_%7B%5Ctext%7Bdata%7D%7D%7D%5B%5Clog+D%28x%29%5D+-+%5Cfrac%7B1%7D%7B2%7DE_z%5B%5Clog%281+-+D%28G%28z%29%29%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
 .
.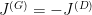 . We simply want to minimize the likelihood of the discriminator for being correct.
. We simply want to minimize the likelihood of the discriminator for being correct.![J^{(G)} = -\frac{1}{2}E_z[\log D(G(z))]](https://s0.wp.com/latex.php?latex=J%5E%7B%28G%29%7D+%3D+-%5Cfrac%7B1%7D%7B2%7DE_z%5B%5Clog+D%28G%28z%29%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
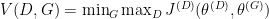
![C(G) = \max_D V(D,G) = E_{x \sim p_{\text{data}}}[\log D^*(x)] + E_z[\log(1 - D^*(G(z)))]](https://s0.wp.com/latex.php?latex=C%28G%29+%3D+%5Cmax_D%C2%A0V%28D%2CG%29+%3D%C2%A0E_%7Bx+%5Csim+p_%7B%5Ctext%7Bdata%7D%7D%7D%5B%5Clog+D%5E%2A%28x%29%5D+%2B+E_z%5B%5Clog%281+-+D%5E%2A%28G%28z%29%29%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
![C(G) = \max_D V(D,G) = E_{x \sim p_{\text{data}}}[\log (\frac{p_{\text{data}}}{p_{\text{data}} + p_{\text{model}}})] + E_z[\log(\frac{p_{\text{model}}}{p_{\text{data}} + p_{\text{model}}})]](https://s0.wp.com/latex.php?latex=C%28G%29+%3D+%5Cmax_D%C2%A0V%28D%2CG%29+%3D%C2%A0E_%7Bx+%5Csim+p_%7B%5Ctext%7Bdata%7D%7D%7D%5B%5Clog+%28%5Cfrac%7Bp_%7B%5Ctext%7Bdata%7D%7D%7D%7Bp_%7B%5Ctext%7Bdata%7D%7D+%2B+p_%7B%5Ctext%7Bmodel%7D%7D%7D%29%5D+%2B+E_z%5B%5Clog%28%5Cfrac%7Bp_%7B%5Ctext%7Bmodel%7D%7D%7D%7Bp_%7B%5Ctext%7Bdata%7D%7D+%2B+p_%7B%5Ctext%7Bmodel%7D%7D%7D%29%5D&bg=ffffff&fg=000&s=0&c=20201002)