This paper is similar to collaborative topic modeling. They also mentioned that in their paper. The main difference is they train LDA offline so the topic distribution is not affected by tagging (supervisory signals).
From probabilistic perspective, it is variant of CTM:
Train topic model offline.
- For each doc y_j in Corpus:
1. Draw latent offset, e ~ Gaussian(0, 1)
2. Draw document latent, y ~ e + topic(y) - For each tag u_i:
1. Draw tag, u_i, from Gaussian(0, 1) - For each doc y_j and tag u_i:
1. Draw a document label, t_{i,j} ~ Gaussian( u_i * y_j , confidence)
I think the confidence matrix that they create is simply a fixed variance.
From matrix factorization perspective:
1. They factor a tagging matrix: T = U * Y
2. Add regularizer || U ||^2 to keep U small since U is drawn from Gaussian(0,1).
3. Add regularizer that penalizes when Y is deviate from a topic(Y).
Their binarization from Y to hashcode is very straight forward.
Based on my analysis, there are a lot of rooms to improve:
1. adding non-linearity to matrix factorization, hash code function, and binarization function.
2. tagging uncertainty is learned from the data (instead of fixed variances).
3. tags (supervisory signal) can be correlated ( so document without tag t, can still have a high probability for tag t, if similar tag s appears in the doc.
4. jointly learn a topic model.
References
References:
[1] Wang, Qifan, Dan Zhang, and Luo Si. “Semantic hashing using tags and topic modeling.” Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval. ACM, 2013.
 if image i is semantically similar to image j. Otherwise,
if image i is semantically similar to image j. Otherwise,  . Then they cleverly assume that a dot product between two hash code ( a binary vector) is approximately equivalent to +q if both vectors are similar. q is a dimension of a binary vector. The objective function then becomes a matrix factorization problem:
. Then they cleverly assume that a dot product between two hash code ( a binary vector) is approximately equivalent to +q if both vectors are similar. q is a dimension of a binary vector. The objective function then becomes a matrix factorization problem: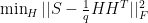 where
where 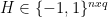
![H \in [-1, 1 ]^{n x q}](https://s0.wp.com/latex.php?latex=H+%5Cin+%5B-1%2C+1+%5D%5E%7Bn+x+q%7D&bg=ffffff&fg=000&s=0&c=20201002) , which is easier to optimize using a coordinate descent algorithm using Newton direction. The contribution is the derivation of efficient optimization algorithms that learn an approximate hashcode from the range constraint.
, which is easier to optimize using a coordinate descent algorithm using Newton direction. The contribution is the derivation of efficient optimization algorithms that learn an approximate hashcode from the range constraint.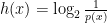
![H(X) = -\sum_x p(x) \log_2 p(x) = E[- \log_2 p(x) ]](https://s0.wp.com/latex.php?latex=H%28X%29+%3D+-%5Csum_x+p%28x%29+%5Clog_2+p%28x%29+%C2%A0%3D+E%5B-+%5Clog_2+p%28x%29+%5D&bg=ffffff&fg=000&s=0&c=20201002)
![KL(P||Q) = \sum_x p(x) \log_2 \frac{p(x)}{q(x)} = E[\log_2 \frac{p(x)}{q(x)}]](https://s0.wp.com/latex.php?latex=KL%28P%7C%7CQ%29+%3D+%5Csum_x+p%28x%29+%5Clog_2+%5Cfrac%7Bp%28x%29%7D%7Bq%28x%29%7D+%3D+E%5B%5Clog_2+%5Cfrac%7Bp%28x%29%7D%7Bq%28x%29%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)



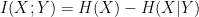



![\log p(x) = \log \int_z p(x, z) dz = \log E_{q(z)}[\frac{p(x,z)}{q(z)}]](https://s0.wp.com/latex.php?latex=%5Clog+p%28x%29+%3D+%5Clog+%5Cint_z+p%28x%2C+z%29+dz+%3D+%5Clog+E_%7Bq%28z%29%7D%5B%5Cfrac%7Bp%28x%2Cz%29%7D%7Bq%28z%29%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
![>= E_{q(z)}[\log p(x, z) ]- E_{q(z)}[ \log q(z) ]](https://s0.wp.com/latex.php?latex=%3E%3D+E_%7Bq%28z%29%7D%5B%5Clog+p%28x%2C+z%29+%5D-+E_%7Bq%28z%29%7D%5B+%5Clog+q%28z%29+%5D&bg=ffffff&fg=000&s=0&c=20201002)
 , the entropy term is just a sum of entropy for each hidden variables.
, the entropy term is just a sum of entropy for each hidden variables.![\log p(x) >= E_{q(z)}[\log p(x| z) ] + E_{q(z)}[\log p(z)]- E_{q(z)}[ \log q(z) ]](https://s0.wp.com/latex.php?latex=%5Clog+p%28x%29+%3E%3D+E_%7Bq%28z%29%7D%5B%5Clog+p%28x%7C+z%29+%5D+%2B+E_%7Bq%28z%29%7D%5B%5Clog+p%28z%29%5D-+E_%7Bq%28z%29%7D%5B+%5Clog+q%28z%29+%5D&bg=ffffff&fg=000&s=0&c=20201002)
![= E_{q(z)}[\log p(x| z) ] - D_{kl}(q(z)||p(z))](https://s0.wp.com/latex.php?latex=%3D+E_%7Bq%28z%29%7D%5B%5Clog+p%28x%7C+z%29+%5D+-+D_%7Bkl%7D%28q%28z%29%7C%7Cp%28z%29%29&bg=ffffff&fg=000&s=0&c=20201002)
 is a uniform distribution, then it is useless because we cannot make any good prediction. Thus, we want
is a uniform distribution, then it is useless because we cannot make any good prediction. Thus, we want 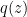 to be less flat which automatically means more predictable and lower entropy.
to be less flat which automatically means more predictable and lower entropy.