The order embedding paper mentioned the prior work to learn word embedding in a probabilistic way. This idea has intrigued me so I went back to read this ICLR paper. Not surprisingly, this pioneered paper was written by the student of Andrew McCallum. I am expecting a few surprises and an aha moment from this work.
This picture explains everything about Gaussian word embedding:

In word2vec, the model attempts to learn a fixed vector so that any word in the same sentence has similar vectors. The similarity among vectors is measured by the dot product. The probablistic embedding is a generalization of word2vec. Instead of learning only an embedding vector, the model needs to learn 2 vectors per word; namely mean and variance vectors.
The role of a variance is important. A common word has a higher chance to be appeared with more words than a more specific word. We could expect that a different variety of sentences formed by the common word; hence, its variance should be large.
With this intuition, the covariance matrix of word w could be estimated based on the distance among other words within the same sentence as word w:

is a word vector found in the same sentence as word w
One problem with this estimation is that the model cannot capture many entailing relationships because some broader words are rarely appeared in the text corpus. For example, sentences “look at a dog” and “look at a bird” are far more common than sentence “look at a mammal”. The hierarchical relationship between mammal and dog could not be learned by this model.
Energy-based learning approach (EBM)
This learning framwork is a generalization of a probabilistic model. The probablistic model needs to “stick” with a probabilistic (normalized) distribution, but the energy-based model does not have to. In sum, in EMB framework, we first define a compatible function between a pair of words and use a gradient-based inference to keep the “energy” or score output by the compatible function as small as possible. One key advantage of EBM is its ability to incorporate a latent variable, which is something that can’t be done directly using feedforward networks. For a sake of this post, you will find many resources on EBM approach.
Compatible Function
This paper use an inner product between two Gaussian distributions as a similarity measurement, which is defined as:
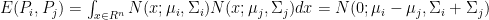
To train the compatible function, the authors depend on log-likelihood estimation. They found that using rank loss or ratios of densities are less interpretable and possibly log-likelihood has a better numerical stability.
Another way to train the model is to use KL divergence as the distance measure. I am not sure if using KL divergence (an asymmetric distance) is applicable because we can force the word w to be closer to its neighbor word but not another way around. I guess when it comes to training the deep learning model, we don’t have to be too strict about some mathetical conditions such as the distance metric.
Learning
The mean needs to be kept as small while a covariance matrix must be positive definite. One constraint is to keep each element of the diagonal to be bounded the hypercube. This can be done by enforcing each element to be bounded some pre-defined range.
Evaluation
A broader word has a higher variance than a specific word.

Entailment
As mentioned earlier, this model can somewhat learn entailment directly from the source data. But it can’t learn all word relationships.
In sum:
It is obvious that the proposed model probably does not work well in the industry. But this paper provides a probabilstic perspective of word embedding. Indeed, this is an interesting paper. I always enjoy reading this paper greatly.
Reference:
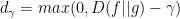





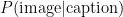 The additional textual data controls where to read and write the image.
The additional textual data controls where to read and write the image. where its mean and variance are functions of the current hidden state of the encoder, e.g.
where its mean and variance are functions of the current hidden state of the encoder, e.g.  . However, AlignDRAW adds dependency between latent variables:
. However, AlignDRAW adds dependency between latent variables: 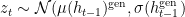 .
. from a prior
from a prior  , but AlignDRAW will draw
, but AlignDRAW will draw  . It means that there is a dependency between each latent vector in AlignDRAW model.
. It means that there is a dependency between each latent vector in AlignDRAW model.
 . Finally, compute the weight average of all hidden state of the language model to obtain the caption context,
. Finally, compute the weight average of all hidden state of the language model to obtain the caption context,  . This context together with a latent vector
. This context together with a latent vector 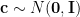
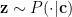
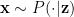
![p(D) = \int p(c) \big[ \prod_{x \in D} \int p(x|z;\theta)p(z|c;\theta)dz \big]dc](https://s0.wp.com/latex.php?latex=p%28D%29+%3D+%5Cint+p%28c%29+%5Cbig%5B+%5Cprod_%7Bx+%5Cin+D%7D+%5Cint+p%28x%7Cz%3B%5Ctheta%29p%28z%7Cc%3B%5Ctheta%29dz+%5Cbig%5Ddc&bg=ffffff&fg=000&s=0&c=20201002)
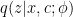 and
and  to optimize a variational lowerbound. The single dataset log likelihood lowerboud is:
to optimize a variational lowerbound. The single dataset log likelihood lowerboud is:![\mathcal{L}_D = E_{q(c|D;\phi)}\big[ \sum_{x \in d} E_{q(z|c, x; \phi)}[ \log p(x|z;\theta)] - D_{KL}(q(z|c,x;\phi)||p(z|c;\theta)) \big] - D_{KL}(q(c|D;\phi)||p(c))](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BL%7D_D+%3D+E_%7Bq%28c%7CD%3B%5Cphi%29%7D%5Cbig%5B%C2%A0+%5Csum_%7Bx+%5Cin+d%7D+E_%7Bq%28z%7Cc%2C+x%3B+%5Cphi%29%7D%5B+%5Clog+p%28x%7Cz%3B%5Ctheta%29%5D+-+D_%7BKL%7D%28q%28z%7Cc%2Cx%3B%5Cphi%29%7C%7Cp%28z%7Cc%3B%5Ctheta%29%29+%5Cbig%5D+-+D_%7BKL%7D%28q%28c%7CD%3B%5Cphi%29%7C%7Cp%28c%29%29&bg=ffffff&fg=000&s=0&c=20201002)
 . Then, add a pool layer to aggregate
. Then, add a pool layer to aggregate 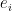 into a single vector. This paper uses an element-wise mean. Finally, the final vector is used to generate parameters of a diagonal Gaussian.
into a single vector. This paper uses an element-wise mean. Finally, the final vector is used to generate parameters of a diagonal Gaussian.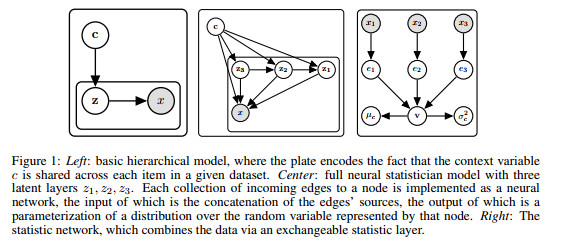
![\log P(\textbf{x}) \ge E_{Q(\textbf{z}|\textbf{x})}[\log \frac{P(\textbf{x},\textbf{z})}{Q(\textbf{z}|\textbf{x})}] = L(x)](https://s0.wp.com/latex.php?latex=%5Clog+P%28%5Ctextbf%7Bx%7D%29+%5Cge+E_%7BQ%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Clog+%5Cfrac%7BP%28%5Ctextbf%7Bx%7D%2C%5Ctextbf%7Bz%7D%29%7D%7BQ%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5D+%3D+L%28x%29&bg=ffffff&fg=000&s=0&c=20201002)
 is:
is:

![\log P(\textbf{x}) \ge E_{\textbf{z}_1,\textbf{z}_2, \cdots, \textbf{z}_k \sim Q(\textbf{z}|\textbf{x})}[\log \frac{1}{k}\sum_{i=1}^k \frac{P(\textbf{x},\textbf{z}_i)}{Q(\textbf{z}_i|\textbf{x})}]](https://s0.wp.com/latex.php?latex=%5Clog+P%28%5Ctextbf%7Bx%7D%29+%5Cge+E_%7B%5Ctextbf%7Bz%7D_1%2C%5Ctextbf%7Bz%7D_2%2C+%5Ccdots%2C+%5Ctextbf%7Bz%7D_k+%5Csim+Q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Clog+%5Cfrac%7B1%7D%7Bk%7D%5Csum_%7Bi%3D1%7D%5Ek+%5Cfrac%7BP%28%5Ctextbf%7Bx%7D%2C%5Ctextbf%7Bz%7D_i%29%7D%7BQ%28%5Ctextbf%7Bz%7D_i%7C%5Ctextbf%7Bx%7D%29%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\nabla_{\theta} L_k(\textbf{x}) = \nabla_{\theta} E_{\textbf{z}_1,\textbf{z}_2, \cdots, \textbf{z}_k \sim Q(\textbf{z}|\textbf{x})}[\log\frac{1}{k}\sum_{i=1}^k w(\textbf{x}, \textbf{z}_i; \theta))] \\ = E_{\textbf{z}_1,\textbf{z}_2, \cdots, \textbf{z}_k \sim Q(\textbf{z}|\textbf{x})}[\nabla_{\theta} \log\frac{1}{k}\sum_{i=1}^k w(\textbf{x}, \textbf{z}_i; \theta))] \\ = E_{\textbf{z}_1,\textbf{z}_2, \cdots, \textbf{z}_k \sim Q(\textbf{z}|\textbf{x})}[\frac{\nabla_{\theta}\frac{1}{k}\sum_{i=1}^k w(\textbf{x}, \textbf{z}_i; \theta))}{\frac{1}{k}\sum_{i=1}^k w(\textbf{x}, \textbf{z}_i; \theta)}] \\ = E_{\textbf{z}_1,\textbf{z}_2, \cdots, \textbf{z}_k \sim Q(\textbf{z}|\textbf{x})}[\frac{\nabla_{\theta}\frac{1}{k}\sum_{i=1}^k w(\textbf{x}, \textbf{z}_i; \theta))}{\frac{1}{k}\sum_{i=1}^k w(\textbf{x}, \textbf{z}_i; \theta)}] \\= E_{\textbf{z}_1,\textbf{z}_2, \cdots, \textbf{z}_k \sim Q(\textbf{z}|\textbf{x})}[\frac{\nabla_{\theta}\sum_{i=1}^k w(\textbf{x}, \textbf{z}_i; \theta)}{\sum_{i=1}^k w(\textbf{x}, \textbf{z}_i; \theta)}] \\ = E_{\textbf{z}_1,\textbf{z}_2, \cdots, \textbf{z}_k \sim Q(\textbf{z}|\textbf{x})}[\frac{\nabla_{\theta}\sum_{i=1}^k w(\textbf{x}, \textbf{z}_i; \theta)}{C(\textbf{x};\theta)}] \\ = E_{\textbf{z}_1,\textbf{z}_2, \cdots, \textbf{z}_k \sim Q(\textbf{z}|\textbf{x})}[\frac{\sum_{i=1}^k \nabla_{\theta} w(\textbf{x}, \textbf{z}_i; \theta)}{C(\textbf{x};\theta)}]](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7D+L_k%28%5Ctextbf%7Bx%7D%29+%3D+%5Cnabla_%7B%5Ctheta%7D+E_%7B%5Ctextbf%7Bz%7D_1%2C%5Ctextbf%7Bz%7D_2%2C+%5Ccdots%2C+%5Ctextbf%7Bz%7D_k+%5Csim+Q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Clog%5Cfrac%7B1%7D%7Bk%7D%5Csum_%7Bi%3D1%7D%5Ek+w%28%5Ctextbf%7Bx%7D%2C+%5Ctextbf%7Bz%7D_i%3B+%5Ctheta%29%29%5D+%5C%5C+%3D+E_%7B%5Ctextbf%7Bz%7D_1%2C%5Ctextbf%7Bz%7D_2%2C+%5Ccdots%2C+%5Ctextbf%7Bz%7D_k+%5Csim+Q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Cnabla_%7B%5Ctheta%7D+%5Clog%5Cfrac%7B1%7D%7Bk%7D%5Csum_%7Bi%3D1%7D%5Ek+w%28%5Ctextbf%7Bx%7D%2C+%5Ctextbf%7Bz%7D_i%3B+%5Ctheta%29%29%5D+%5C%5C+%3D+E_%7B%5Ctextbf%7Bz%7D_1%2C%5Ctextbf%7Bz%7D_2%2C+%5Ccdots%2C+%5Ctextbf%7Bz%7D_k+%5Csim+Q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Cfrac%7B%5Cnabla_%7B%5Ctheta%7D%5Cfrac%7B1%7D%7Bk%7D%5Csum_%7Bi%3D1%7D%5Ek+w%28%5Ctextbf%7Bx%7D%2C+%5Ctextbf%7Bz%7D_i%3B+%5Ctheta%29%29%7D%7B%5Cfrac%7B1%7D%7Bk%7D%5Csum_%7Bi%3D1%7D%5Ek+w%28%5Ctextbf%7Bx%7D%2C+%5Ctextbf%7Bz%7D_i%3B+%5Ctheta%29%7D%5D+%5C%5C+%3D+E_%7B%5Ctextbf%7Bz%7D_1%2C%5Ctextbf%7Bz%7D_2%2C+%5Ccdots%2C+%5Ctextbf%7Bz%7D_k+%5Csim+Q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Cfrac%7B%5Cnabla_%7B%5Ctheta%7D%5Cfrac%7B1%7D%7Bk%7D%5Csum_%7Bi%3D1%7D%5Ek+w%28%5Ctextbf%7Bx%7D%2C+%5Ctextbf%7Bz%7D_i%3B+%5Ctheta%29%29%7D%7B%5Cfrac%7B1%7D%7Bk%7D%5Csum_%7Bi%3D1%7D%5Ek+w%28%5Ctextbf%7Bx%7D%2C+%5Ctextbf%7Bz%7D_i%3B+%5Ctheta%29%7D%5D+%5C%5C%3D+E_%7B%5Ctextbf%7Bz%7D_1%2C%5Ctextbf%7Bz%7D_2%2C+%5Ccdots%2C+%5Ctextbf%7Bz%7D_k+%5Csim+Q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Cfrac%7B%5Cnabla_%7B%5Ctheta%7D%5Csum_%7Bi%3D1%7D%5Ek+w%28%5Ctextbf%7Bx%7D%2C+%5Ctextbf%7Bz%7D_i%3B+%5Ctheta%29%7D%7B%5Csum_%7Bi%3D1%7D%5Ek+w%28%5Ctextbf%7Bx%7D%2C+%5Ctextbf%7Bz%7D_i%3B+%5Ctheta%29%7D%5D+%5C%5C+%3D+E_%7B%5Ctextbf%7Bz%7D_1%2C%5Ctextbf%7Bz%7D_2%2C+%5Ccdots%2C+%5Ctextbf%7Bz%7D_k+%5Csim+Q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Cfrac%7B%5Cnabla_%7B%5Ctheta%7D%5Csum_%7Bi%3D1%7D%5Ek+w%28%5Ctextbf%7Bx%7D%2C+%5Ctextbf%7Bz%7D_i%3B+%5Ctheta%29%7D%7BC%28%5Ctextbf%7Bx%7D%3B%5Ctheta%29%7D%5D+%5C%5C+%3D+E_%7B%5Ctextbf%7Bz%7D_1%2C%5Ctextbf%7Bz%7D_2%2C+%5Ccdots%2C+%5Ctextbf%7Bz%7D_k+%5Csim+Q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Cfrac%7B%5Csum_%7Bi%3D1%7D%5Ek+%5Cnabla_%7B%5Ctheta%7D+w%28%5Ctextbf%7Bx%7D%2C+%5Ctextbf%7Bz%7D_i%3B+%5Ctheta%29%7D%7BC%28%5Ctextbf%7Bx%7D%3B%5Ctheta%29%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
![= E_{\textbf{z}_1,\textbf{z}_2, \cdots, \textbf{z}_k \sim Q(\textbf{z}|\textbf{x})}[\frac{\sum_{i=1}^k w(\textbf{x}, \textbf{z}_i; \theta)\nabla_{\theta}\log w(\textbf{x}, \textbf{z}_i; \theta)}{C(\textbf{x};\theta)}] \\ = E_{\textbf{z}_1,\textbf{z}_2, \cdots, \textbf{z}_k \sim Q(\textbf{z}|\textbf{x})}[\sum_{i=1}^k \frac{w(\textbf{x}, \textbf{z}_i; \theta)}{\sum_{i=1}^k w(\textbf{x}, \textbf{z}_i; \theta)}\nabla_{\theta}\log w(\textbf{x}, \textbf{z}_i; \theta)] \\ = E_{\textbf{z}_1,\textbf{z}_2, \cdots, \textbf{z}_k \sim Q(\textbf{z}|\textbf{x})}[\sum_{i=1}^k \tilde w_i\nabla_{\theta}\log w(\textbf{x}, \textbf{z}_i; \theta)]](https://s0.wp.com/latex.php?latex=%3D+E_%7B%5Ctextbf%7Bz%7D_1%2C%5Ctextbf%7Bz%7D_2%2C+%5Ccdots%2C+%5Ctextbf%7Bz%7D_k+%5Csim+Q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Cfrac%7B%5Csum_%7Bi%3D1%7D%5Ek+w%28%5Ctextbf%7Bx%7D%2C+%5Ctextbf%7Bz%7D_i%3B+%5Ctheta%29%5Cnabla_%7B%5Ctheta%7D%5Clog+w%28%5Ctextbf%7Bx%7D%2C+%5Ctextbf%7Bz%7D_i%3B+%5Ctheta%29%7D%7BC%28%5Ctextbf%7Bx%7D%3B%5Ctheta%29%7D%5D+%5C%5C+%3D+E_%7B%5Ctextbf%7Bz%7D_1%2C%5Ctextbf%7Bz%7D_2%2C+%5Ccdots%2C+%5Ctextbf%7Bz%7D_k+%5Csim+Q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Csum_%7Bi%3D1%7D%5Ek+%5Cfrac%7Bw%28%5Ctextbf%7Bx%7D%2C+%5Ctextbf%7Bz%7D_i%3B+%5Ctheta%29%7D%7B%5Csum_%7Bi%3D1%7D%5Ek+w%28%5Ctextbf%7Bx%7D%2C+%5Ctextbf%7Bz%7D_i%3B+%5Ctheta%29%7D%5Cnabla_%7B%5Ctheta%7D%5Clog+w%28%5Ctextbf%7Bx%7D%2C+%5Ctextbf%7Bz%7D_i%3B+%5Ctheta%29%5D+%5C%5C+%3D+E_%7B%5Ctextbf%7Bz%7D_1%2C%5Ctextbf%7Bz%7D_2%2C+%5Ccdots%2C+%5Ctextbf%7Bz%7D_k+%5Csim+Q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Csum_%7Bi%3D1%7D%5Ek+%5Ctilde+w_i%5Cnabla_%7B%5Ctheta%7D%5Clog+w%28%5Ctextbf%7Bx%7D%2C+%5Ctextbf%7Bz%7D_i%3B+%5Ctheta%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
 . The Markov assumption is necessary to keep the inference tractable. The shortcoming is the limitation of the context windows. The higher order Markov assumption makes an inferencing becomes more difficult.
. The Markov assumption is necessary to keep the inference tractable. The shortcoming is the limitation of the context windows. The higher order Markov assumption makes an inferencing becomes more difficult.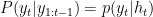 where
where 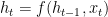 . Basically,
. Basically,  is a summarization of the preceding words and it uses this information to predict the current word. The RNN-based language model works pretty well but it has difficulty with long-range dependency due to the difficulty in optimization and overfitting.
is a summarization of the preceding words and it uses this information to predict the current word. The RNN-based language model works pretty well but it has difficulty with long-range dependency due to the difficulty in optimization and overfitting.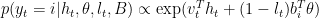
 turn on and off the topic vector
turn on and off the topic vector  .
.
You must be logged in to post a comment.