“Pentagon is a hexagon without one side.” – Joseph Gilley
Searching on the map data is more challenging than a typical document search. Geolocation and potentially time are additional dimensions that must be considered when dealing with this complex search.
Mapping geolocation to a grid
The first step is to map all locations on the earth into a 2-d space. Mathematically, it needs to map a sphere to a flat surface. There are a lot of ways to do this type of projection. They use Dymaxion projection. They use an icosahedron so that they can project a sphere to a plane. Google S3 uses a cube but Uber claims that icosahedron is a better choice.
The benefit of using the icosahedron is to reduce the distortion. The larger angle of the projection, the more distortion. Projecting on an icosahedron has the smallest angles of the projection. The orientation of the projection is also important. There is only one orientation such that all the vertices are in the water. Since the location near the vertex has the highest distortion, this orientation reduces the distortion on any land surface.
Why a hexagon is used as a tiling unit?

- neighbor traversal
- The neighbors are always a grid that shares the same edge. It is harder to determine the neighbors using a triangle or rectangle.
- subdivision
- It is easier to create a larger grid by composing smaller hexagons.
- distortion
- It has less distortion compared to a rectangle.
One interesting hack is to tile the globe with hexagons but they need 12 pentagons.
Reference:

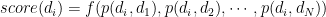 They tried different aggregation function
They tried different aggregation function  and shows that summing and binary function work quite well.
and shows that summing and binary function work quite well. 







 and
and  . The objective function is to maximize the similarity between the source word
. The objective function is to maximize the similarity between the source word  and the target word
and the target word  :
: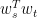 should be high if both words appear in the same context window.
should be high if both words appear in the same context window.
You must be logged in to post a comment.