Here is the proof showing that the KL divergence of two distributions 

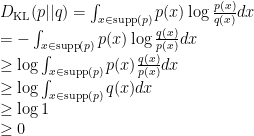
The key step is to apply the Jensen’s inequality so that the logarithm will be placed outside of the integration.
Here is the proof showing that the KL divergence of two distributions
The key step is to apply the Jensen’s inequality so that the logarithm will be placed outside of the integration.
Does adding more stochastic layers to the recognition model (encoder function) give a tighter lower-bound? Daniel Jiwoong (Bengio’s student)’s AAAI paper, “Denoising Criterion for Variational Auto-Encoding Framework. (AAAI 2017)”, claims that this is true.
It has been known that multi-modal recognition models can learn a more complex posterior distribution from the input data (see [2], [3]). Intuitively, adding more stochastic layers increases the complexity of the recognition models.
This proof shows that the following inequality is true:
By using the KL divergence property, which is defined as:
Since KL divergence is always non-negative (you can also prove that too.), arranging the inequality will result in the following expression:
Hence,
This statement says that the cross entropy for 

A feedforward network with multiple stochastic layers can be defined as a marginal distribution of multiple latent variables:
Then,
We will prove that left and right inequality are satisfied.
We start with the right inequality by simplifying the expression:
From Lemma 0: if we replace 

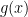
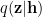
This shows that the right inequality is satisfied.
We expand the encoder function
According to the Jensen’s inequality:
The left inequality is also satisfied.
I went over the proof presented in the paper, “Denoising Criterion for Variational Auto-Encoding Framework”. The simple proof on adding one extra stochastic layer shows that we get a tighter lowerbound. The original paper also generalizes its claim to L stochastic layers. By following the same proof strategy, they show that the lowerbound will be tighter as we add more stochastic layers.
Reference:
[1] Im, Daniel Jiwoong, et al. “Denoising Criterion for Variational Auto-Encoding Framework.” AAAI. 2017.
[2] Kingma, Diederik P., et al. “Improved variational inference with inverse autoregressive flow.” Advances in Neural Information Processing Systems. 2016.
[3] Dinh, Laurent, Jascha Sohl-Dickstein, and Samy Bengio. “Density estimation using Real NVP.” arXiv preprint arXiv:1605.08803 (2016).
![E_{f(x)}[\log f(x)] \ge E_{f(x)}[\log g(x)]](https://s0.wp.com/latex.php?latex=E_%7Bf%28x%29%7D%5B%5Clog+f%28x%29%5D+%5Cge+E_%7Bf%28x%29%7D%5B%5Clog+g%28x%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
![D_{KL}(f || g) = \int_x f(x) \log \frac{f(x)}{g(x)} dx = E_{f(x)}[ \log \frac{f(x)}{g(x)} ] \ge 0](https://s0.wp.com/latex.php?latex=D_%7BKL%7D%28f+%7C%7C+g%29+%3D+%5Cint_x+f%28x%29+%5Clog+%5Cfrac%7Bf%28x%29%7D%7Bg%28x%29%7D+dx+%3D+E_%7Bf%28x%29%7D%5B+%5Clog+%5Cfrac%7Bf%28x%29%7D%7Bg%28x%29%7D+%5D+%5Cge+0&bg=ffffff&fg=000&s=0&c=20201002)
![E_{f(x)}[ \log f(x)] - E_{f(x)}[ \log g(x)] \ge 0](https://s0.wp.com/latex.php?latex=E_%7Bf%28x%29%7D%5B+%5Clog+f%28x%29%5D+-+E_%7Bf%28x%29%7D%5B+%5Clog+g%28x%29%5D+%5Cge+0&bg=ffffff&fg=000&s=0&c=20201002)
![E_{f(x)}[ \log f(x)] \ge E_{f(x)}[ \log g(x)]](https://s0.wp.com/latex.php?latex=E_%7Bf%28x%29%7D%5B+%5Clog+f%28x%29%5D+%5Cge+E_%7Bf%28x%29%7D%5B+%5Clog+g%28x%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
![q(\textbf{z}|\textbf{x}) = \int_{\textbf{h}}q(\textbf{z}|\textbf{h})q(\textbf{h}|\textbf{x})d\textbf{h} = E_{q(\textbf{h}|\textbf{x})}[q(\textbf{z}|\textbf{h})]](https://s0.wp.com/latex.php?latex=q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29+%3D+%5Cint_%7B%5Ctextbf%7Bh%7D%7Dq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bh%7D%29q%28%5Ctextbf%7Bh%7D%7C%5Ctextbf%7Bx%7D%29d%5Ctextbf%7Bh%7D+%3D+E_%7Bq%28%5Ctextbf%7Bh%7D%7C%5Ctextbf%7Bx%7D%29%7D%5Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bh%7D%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\log p(\textbf{x}) \ge E_{q(\textbf{z}|\textbf{x})}[\log \frac{p(\textbf{x},\textbf{z})}{q(\textbf{z}|\textbf{h})}] \ge E_{q(\textbf{z}|\textbf{x})}[\log \frac{p(\textbf{x},\textbf{z})}{q(\textbf{z}|\textbf{x})}]](https://s0.wp.com/latex.php?latex=%5Clog+p%28%5Ctextbf%7Bx%7D%29+%5Cge+E_%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Clog+%5Cfrac%7Bp%28%5Ctextbf%7Bx%7D%2C%5Ctextbf%7Bz%7D%29%7D%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bh%7D%29%7D%5D+%5Cge+E_%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Clog+%5Cfrac%7Bp%28%5Ctextbf%7Bx%7D%2C%5Ctextbf%7Bz%7D%29%7D%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
![E_{q(\textbf{z}|\textbf{x})}[\log p(\textbf{x},\textbf{z})]- E_{q(\textbf{z}|\textbf{x})}[q(\textbf{z}|\textbf{h})] \ge E_{q(\textbf{z}|\textbf{x})}[\log p(\textbf{x},\textbf{z})]-E_{q(\textbf{z}|\textbf{x})}[\log q(\textbf{z}|\textbf{x})]](https://s0.wp.com/latex.php?latex=E_%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Clog+p%28%5Ctextbf%7Bx%7D%2C%5Ctextbf%7Bz%7D%29%5D-+E_%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bh%7D%29%5D+%5Cge+E_%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Clog+p%28%5Ctextbf%7Bx%7D%2C%5Ctextbf%7Bz%7D%29%5D-E_%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Clog+q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
![E_{q(\textbf{z}|\textbf{x})}[\log q(\textbf{z}|\textbf{x})] \ge E_{q(\textbf{z}|\textbf{x})}[\log q(\textbf{z}|\textbf{h})]](https://s0.wp.com/latex.php?latex=E_%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Clog+q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%5D+%5Cge+E_%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Clog+q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bh%7D%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
![E_{q(\textbf{z}|\textbf{x})}[\log \frac{p(\textbf{x},\textbf{z})}{q(z|\textbf{x})}] = \int_\textbf{z} q(\textbf{z}|\textbf{x})\log \frac{p(\textbf{x},\textbf{z})}{q(\textbf{z}|\textbf{x})}d\textbf{z} \\ = \int_\textbf{z} \int_h q(\textbf{z}|\textbf{h})q(\textbf{h}|\textbf{z})\log \frac{p(\textbf{x},\textbf{z})}{q(\textbf{z}|\textbf{x})}d\textbf{z} d\textbf{h} \\ = E_{q(\textbf{z}|\textbf{h})}E_{q(\textbf{h}|\textbf{x})}[\log \frac{p(\textbf{x},\textbf{z})}{q(\textbf{z}|\textbf{x})}]](https://s0.wp.com/latex.php?latex=E_%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Clog+%5Cfrac%7Bp%28%5Ctextbf%7Bx%7D%2C%5Ctextbf%7Bz%7D%29%7D%7Bq%28z%7C%5Ctextbf%7Bx%7D%29%7D%5D+%3D+%5Cint_%5Ctextbf%7Bz%7D+q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%5Clog+%5Cfrac%7Bp%28%5Ctextbf%7Bx%7D%2C%5Ctextbf%7Bz%7D%29%7D%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7Dd%5Ctextbf%7Bz%7D+%5C%5C+%3D+%5Cint_%5Ctextbf%7Bz%7D+%5Cint_h+q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bh%7D%29q%28%5Ctextbf%7Bh%7D%7C%5Ctextbf%7Bz%7D%29%5Clog+%5Cfrac%7Bp%28%5Ctextbf%7Bx%7D%2C%5Ctextbf%7Bz%7D%29%7D%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7Dd%5Ctextbf%7Bz%7D+d%5Ctextbf%7Bh%7D+%5C%5C+%3D+E_%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bh%7D%29%7DE_%7Bq%28%5Ctextbf%7Bh%7D%7C%5Ctextbf%7Bx%7D%29%7D%5B%5Clog+%5Cfrac%7Bp%28%5Ctextbf%7Bx%7D%2C%5Ctextbf%7Bz%7D%29%7D%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bx%7D%29%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
![E_{q(\textbf{h}|\textbf{x})}E_{q(\textbf{z}|\textbf{h})}[\log \frac{p(\textbf{x},\textbf{z})}{q(\textbf{z}|\textbf{h})}] \le \log E_{q(\textbf{h}|\textbf{x})}E_{q(\textbf{z}|\textbf{h})}[\frac{p(\textbf{x},\textbf{z})}{q(\textbf{z}|\textbf{h})}] \\ = \log E_{q(\textbf{h}|\textbf{x})}\int_{\textbf{z}} q(\textbf{z}|\textbf{h})[\frac{p(\textbf{x},\textbf{z})}{q(\textbf{z}|\textbf{h})}]d\textbf{z} \\ = \log E_{q(\textbf{h}|\textbf{x})}[p(\textbf{x})] = \log p(\textbf{x})](https://s0.wp.com/latex.php?latex=E_%7Bq%28%5Ctextbf%7Bh%7D%7C%5Ctextbf%7Bx%7D%29%7DE_%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bh%7D%29%7D%5B%5Clog+%5Cfrac%7Bp%28%5Ctextbf%7Bx%7D%2C%5Ctextbf%7Bz%7D%29%7D%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bh%7D%29%7D%5D+%5Cle+%5Clog+E_%7Bq%28%5Ctextbf%7Bh%7D%7C%5Ctextbf%7Bx%7D%29%7DE_%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bh%7D%29%7D%5B%5Cfrac%7Bp%28%5Ctextbf%7Bx%7D%2C%5Ctextbf%7Bz%7D%29%7D%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bh%7D%29%7D%5D+%5C%5C+%3D+%5Clog+E_%7Bq%28%5Ctextbf%7Bh%7D%7C%5Ctextbf%7Bx%7D%29%7D%5Cint_%7B%5Ctextbf%7Bz%7D%7D+q%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bh%7D%29%5B%5Cfrac%7Bp%28%5Ctextbf%7Bx%7D%2C%5Ctextbf%7Bz%7D%29%7D%7Bq%28%5Ctextbf%7Bz%7D%7C%5Ctextbf%7Bh%7D%29%7D%5Dd%5Ctextbf%7Bz%7D+%5C%5C+%3D+%5Clog+E_%7Bq%28%5Ctextbf%7Bh%7D%7C%5Ctextbf%7Bx%7D%29%7D%5Bp%28%5Ctextbf%7Bx%7D%29%5D+%3D+%5Clog+p%28%5Ctextbf%7Bx%7D%29&bg=ffffff&fg=000&s=0&c=20201002)
