Here are my note on some concepts from self-study on Information Theory:
The Shannon information content:
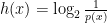
This is a measurement of the information content of the event x = a. For example, when we flip a coin, an event of landing a head is 0.5, then h(x=’head’) = 1. It means that we only need one bit for this event. E.g. If we landed a tail, we know that it won’t be a head. One bit is sufficient.
Entropy: an average of Shannon information:
![H(X) = -\sum_x p(x) \log_2 p(x) = E[- \log_2 p(x) ]](https://s0.wp.com/latex.php?latex=H%28X%29+%3D+-%5Csum_x+p%28x%29+%5Clog_2+p%28x%29+%C2%A0%3D+E%5B-+%5Clog_2+p%28x%29+%5D&bg=ffffff&fg=000&s=0&c=20201002)
We consider all events and average out all the Shannon information. Entropy can be thought as an uncertainty. The higher entropy, the more uncertainty of the event. This implies that the Entropy will be maximum when p(x) is a uniform distribution since we can’t make any prediction.
The Relative entropy (KL Divergence)
![KL(P||Q) = \sum_x p(x) \log_2 \frac{p(x)}{q(x)} = E[\log_2 \frac{p(x)}{q(x)}]](https://s0.wp.com/latex.php?latex=KL%28P%7C%7CQ%29+%3D+%5Csum_x+p%28x%29+%5Clog_2+%5Cfrac%7Bp%28x%29%7D%7Bq%28x%29%7D+%3D+E%5B%5Clog_2+%5Cfrac%7Bp%28x%29%7D%7Bq%28x%29%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
KL(P||Q) is always non-negative (Check Gibbs’ inequality). This term will show up often in many machine learning models. It measures how much distribution q(x) diverges from p(x).
The Conditional entropy of X given Y:
This is an average uncertainty that remains about x when y is known. If I know y, then how much I still don’t know about x.

If we average over y:
$latext H(X|Y) = \sum_y p(y) [-\sum_x p(x|y) \log_2 p(x|y) ] = -sum_{x,y} p(x,y) \log p(x|y) $
Chain rule:

Information content of x and y is the information content of x plus information coent of y given x.
Entropy Chain rule:

An uncertainty about X and Y is the uncertainty of X plus uncertainty of Y given X.
Mutual Information:
This term appears often in information retrieval and some machine learning models. This term measures the average reduction in uncertainty about x that results from learning the value of y. E.g. How much I will learn about x once I know about y ? What is an average amount of information that y conveys about x?
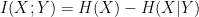

When we add more data, we always decrease uncertainty.


References:
[1] MacKay, David JC. Information theory, inference and learning algorithms. Cambridge university press, 2003.
