My reflection on the GANs for IR tutorial [1], presented by Professor Weinan Zhang.
Generative Adversarial Networks (GANs)[2]
Although we don’t know 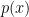
GANs has two components: a generator G and a discriminator D. The generator takes a noise z sampled from a noise prior 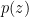

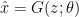
Where 

A good discriminator D should be able to tell if the input data is drawn from the true distribution or is articially contructed.
For the real data, the likelihood of x being detected as real by D should be high:
![\max_{\theta} E_{x \sim p_{\text{true}}}\big[f( D(x; \theta))\big]](https://s0.wp.com/latex.php?latex=%5Cmax_%7B%5Ctheta%7D+E_%7Bx+%5Csim+p_%7B%5Ctext%7Btrue%7D%7D%7D%5Cbig%5Bf%28+D%28x%3B+%5Ctheta%29%29%5Cbig%5D+&bg=ffffff&fg=000&s=0&c=20201002)
For the generated data: the likelihood of D detects $\hat x$ as a real data should be low ( or as generated data should be high):
![\max_{\theta} E_{\hat x \sim \hat p(x; \phi)}\big[ f( 1 - D(\hat x; \theta)) \big]](https://s0.wp.com/latex.php?latex=%5Cmax_%7B%5Ctheta%7D+E_%7B%5Chat+x+%5Csim+%5Chat+p%28x%3B+%5Cphi%29%7D%5Cbig%5B+f%28+1+-+D%28%5Chat+x%3B+%5Ctheta%29%29+%5Cbig%5D&bg=ffffff&fg=000&s=0&c=20201002)
Function f is typically a log function because D can be modeled as a bernoulli distribution.
Meanwhile, generator G should try to generate a new data that D cannot detect. It means G needs to maximize the likelihood that D will make a bad detection:
![\max_{\phi} E_{\hat x \sim \hat p(x)}\big[ f( 1 - D(\hat x; \theta)) \big]](https://s0.wp.com/latex.php?latex=%5Cmax_%7B%5Cphi%7D%C2%A0E_%7B%5Chat+x+%5Csim+%5Chat+p%28x%29%7D%5Cbig%5B+f%28+1+-+D%28%5Chat+x%3B+%5Ctheta%29%29+%5Cbig%5D&bg=ffffff&fg=000&s=0&c=20201002)
Hence, the objective function of GANs is bi-level:
![\max_{\theta, \phi}E_{x \sim p_{\text{true}}}\big[f( D(x; \theta))\big] + E_{\hat x \sim \hat p(x)}\big[ f( 1 - D(\hat x; \theta)) \big]](https://s0.wp.com/latex.php?latex=%5Cmax_%7B%5Ctheta%2C+%5Cphi%7DE_%7Bx+%5Csim+p_%7B%5Ctext%7Btrue%7D%7D%7D%5Cbig%5Bf%28+D%28x%3B+%5Ctheta%29%29%5Cbig%5D%C2%A0+%2B+E_%7B%5Chat+x+%5Csim+%5Chat+p%28x%29%7D%5Cbig%5B+f%28+1+-+D%28%5Chat+x%3B+%5Ctheta%29%29+%5Cbig%5D&bg=ffffff&fg=000&s=0&c=20201002)
Typically, we can iteratively train discriminator and generator. However, training GANs is tricky and very unstable.
With the optimal discriminator D, the lowerbound of the objective function (payoff) is 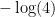
Reference:
[1] http://wnzhang.net/tutorials/sigir2018/docs/sigir18-irgan-full-tutorial.pdf
[2] Goodfellow, I., et al. 2014. Generative adversarial nets. In NIPS 2014.

![\max_{\theta} E_{x \sim p(x)}\big[ \log q_{\theta}(x) \big]](https://s0.wp.com/latex.php?latex=%5Cmax_%7B%5Ctheta%7D+E_%7Bx+%5Csim+p%28x%29%7D%5Cbig%5B+%5Clog+q_%7B%5Ctheta%7D%28x%29+%5Cbig%5D&bg=ffffff&fg=000&s=0&c=20201002)
 can nicely fit the data sampled from the true distribution as much as possible.
can nicely fit the data sampled from the true distribution as much as possible. and
and ![\max_{\theta} E_{x \sim q(x)} \big[ \log p(x) \big]](https://s0.wp.com/latex.php?latex=%5Cmax_%7B%5Ctheta%7D+E_%7Bx+%5Csim+q%28x%29%7D+%5Cbig%5B+%5Clog+p%28x%29+%5Cbig%5D&bg=ffffff&fg=000&s=0&c=20201002)
