My reflection on the GANs for IR tutorial [1], presented by Professor Weinan Zhang.
Maximum Likelihood (MLE)
MLE is a basic algorithm for learning a distribution that fits the data:

This expression can be viewed as a Monte Carlo estimation because the train data we have are sampled from a true distribution:
![\max_{\theta} E_{x \sim p(x)}\big[ \log q_{\theta}(x) \big]](https://s0.wp.com/latex.php?latex=%5Cmax_%7B%5Ctheta%7D+E_%7Bx+%5Csim+p%28x%29%7D%5Cbig%5B+%5Clog+q_%7B%5Ctheta%7D%28x%29+%5Cbig%5D&bg=ffffff&fg=000&s=0&c=20201002)
In the generative model, what we really care is to approximate the true distribution. So we need to make sure that the learned distribution 
If I know a true distribution 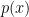

The unfortunate truth is that we don’t know the true distribution
Hence, MLE literally optimizes:
This forces the model to fit the data samples. But let us consider the following objective function:
![\max_{\theta} E_{x \sim q(x)} \big[ \log p(x) \big]](https://s0.wp.com/latex.php?latex=%5Cmax_%7B%5Ctheta%7D+E_%7Bx+%5Csim+q%28x%29%7D+%5Cbig%5B+%5Clog+p%28x%29+%5Cbig%5D&bg=ffffff&fg=000&s=0&c=20201002)
This implies that we want to the generated data to sits on a high-density area of the true distribution. If that is the case, the generated data is very real. This formula makes more sense for the generative model. But again, we don’t know the true distribution
Next post will summarize GANs [2].
Reference:
[1] http://wnzhang.net/tutorials/sigir2018/docs/sigir18-irgan-full-tutorial.pdf
[2] Goodfellow, I., et al. 2014. Generative adversarial nets. In NIPS 2014.
