This paper proposed a deep semantic hashing model that utilizes a generative adversarial network for learning a compact binary code for similar image search task. In semantic hashing research, the supervised models where learning a hash function from labeled images produces more accurate results than unsupervised models. The main reason is that the similarity criteria is not always based on the image contents. It depends on image annotators on how he/she interprets the given image. But obtaining labeled images are expensive, thus, it is important to develop the model that requires less labeled images but still yields a comparable result to a supervised model.
Hence, the goal of this model is to generate more synthetic images in order to learn a better hash function. It leverages the GANs idea by training a conditional generator and discriminator. Intuitively, once we have a good generator that can produce an image given class labels, then we will have more image samples with known labels. GANs framework fits with this semi-supervised learning ideas.
The main model, which is DSH-GANs (Deep Semantic Hashing with GANs), has a generator and discriminator. The input real image must have labels so that we can control the generator to produce similar images (positive samples). We also need to somehow select non-relevant labels so that the generator will produce dissimilar images ( negative samples). Then, these images will go through deep CNN to learn low-level features. Finally, the feature learned from the last layer of CNN will be fed into 3 separated networks. The first one is a hash stream, which is necessary to learn a hash function. They use maximum margin as a rank loss function. The second network is a classification stream. This network is to force images with similar labels to have a similar hash code. For example, two completely different images may have the same labels. Thus, this network allows this two image to end up with the same hash code. Finally, the adversary stream which is part of GANs framework is necessary because we want to adversarial train DSH-GANs.
It is important to pre-train the generator first. The author does not explain the main reason but I think we want the generator at least generate somewhat useful image samples. The pre-train might be helpful for the GANs training to converge to a good local optimal. Pre-training the generator is also based on advertorial training. We want to the generator to generate an image that preserves label information while the discriminator must learn to detect a synthetic image and be able to predict the class label. This pre-training step also utilizes unlabeled images. For any image with no labels, the author set the class label as a zero vector, so that the discriminator just needs to predict all zeros. It seems there is no good reason why choosing zeros because it means that the generator will treat unlabeled images as having labels that are outside the label sets from the corpus.
I think this model utilizes GANs idea well, especially for semi-supervised learning. The key contribution is to allow GANs to generate more image samples in both positive and negative samples.
 if image i is semantically similar to image j. Otherwise,
if image i is semantically similar to image j. Otherwise,  . Then they cleverly assume that a dot product between two hash code ( a binary vector) is approximately equivalent to +q if both vectors are similar. q is a dimension of a binary vector. The objective function then becomes a matrix factorization problem:
. Then they cleverly assume that a dot product between two hash code ( a binary vector) is approximately equivalent to +q if both vectors are similar. q is a dimension of a binary vector. The objective function then becomes a matrix factorization problem: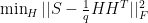 where
where 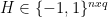
![H \in [-1, 1 ]^{n x q}](https://s0.wp.com/latex.php?latex=H+%5Cin+%5B-1%2C+1+%5D%5E%7Bn+x+q%7D&bg=ffffff&fg=000&s=0&c=20201002) , which is easier to optimize using a coordinate descent algorithm using Newton direction. The contribution is the derivation of efficient optimization algorithms that learn an approximate hashcode from the range constraint.
, which is easier to optimize using a coordinate descent algorithm using Newton direction. The contribution is the derivation of efficient optimization algorithms that learn an approximate hashcode from the range constraint.