The main challenge in many machine learning models is to keep the model up-to-date with the latest dataset. The model refresh frequency could be within a day, an hour, or even a second. With the rapid change in users’ contents and behaviors over the web, the near real-time model training and refreshing are crucial for any organization to recommend relevant products to the key customers. But to achieve this goal has posed a few challenges. This paper proposes a solution to this matter.
Lambda Architecture
This paper is inspired by Lambda architecture. The batch data and real-time data pipeline are aggregated to keep the data as fresh as possible. Can we utilize this idea in the model training? For instance, the spam detector is currently trained on the past month’s datasets. Then the hackers suddenly change the algorithms. Then, the spam coming to the detector will have different characteristics and our detection may fail to catch the spam messages.
The model retraining approach can be classified into 4 levels:
- Stationary problem – train once and done
- code-start retraining – retrain the entire model periodically
- warm-start retraining – retrain a specific component of the model once there is enough data
- nearline retraining – asynchornously nearline on streaming data
Another takeaway is that the training must be lightweight for a near-real-time model refresh while stationary training can be done offline with a much larger accumulated dataset.
Data is collected by taking the features used by the model as soon as the model is used. Then, combine the features with the relevant engagement (click). In their use cases, the ads model scores the given ads. The feature will be saved. Then, as soon as the ad is clicked, the click data will instantaneously be combined with the saved features.
But to re-train the model, the mini-batch should not be too small. Otherwise, the learning will be unstable. Typically, for their application, the mini-batch has 100 examples that could be easily collected in seconds.
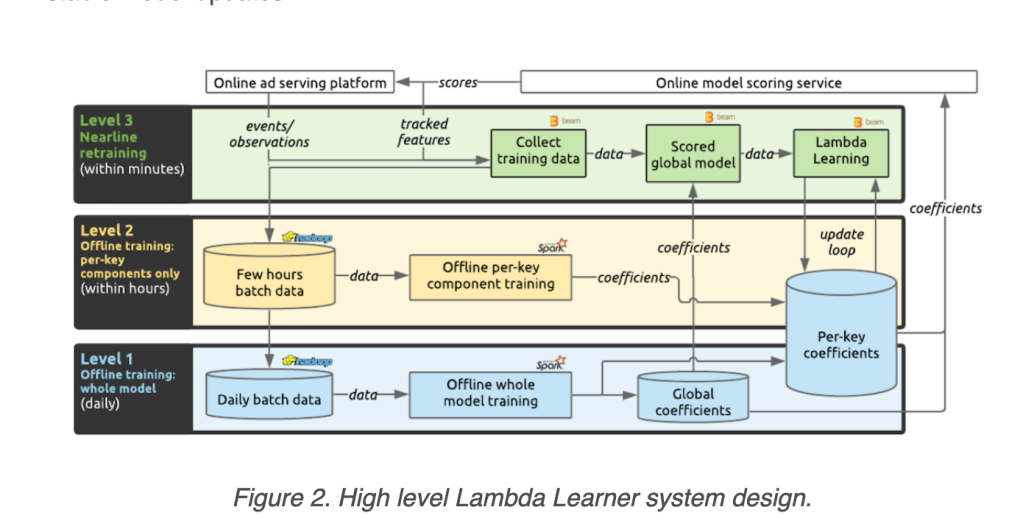
Finally, the near real-time model is not perfect. Although the model performs much better than the model trained offline when there is a change in the data, the model starts to accumulate more and more errors, which eventually degrade the model’s overall performance. The authors observed that the model can last for 60 hours without a full-batch update.
This is a great idea to have an infrastructure to main multiple models with different levels of data freshness. This is suitable for those applications that need to react to the surge of changes.
Reference:


 if
if 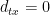
 if
if 
 if
if 
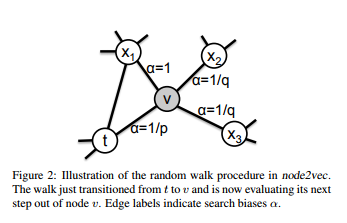
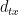 determines the type of visiting nodes. When the distance between the previous node t and the next node x is zero, it means that we return to the node t.
determines the type of visiting nodes. When the distance between the previous node t and the next node x is zero, it means that we return to the node t.

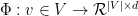 that will maximize the following likelihood function:
that will maximize the following likelihood function:


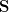 can be factored into two low-rank matrices. The intuition behinds this is that two similar embedding item vector should yield a higher similarity score. The predicted rating of item i by user u is:
can be factored into two low-rank matrices. The intuition behinds this is that two similar embedding item vector should yield a higher similarity score. The predicted rating of item i by user u is:
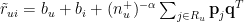
 term is 1.0, the model will average all similarity scores. If all rated items have a high rating, then the predicted rating will likely to be high. On the other hand, when
term is 1.0, the model will average all similarity scores. If all rated items have a high rating, then the predicted rating will likely to be high. On the other hand, when 
You must be logged in to post a comment.