One major limitation of monoBert is its inability to process a long document. monoBert truncates the concatenation of query and document tokens within 512 tokens. This could be a sub-optimal when we are dealing with a long document. There are many works recently propose a solution for applying Bert for a long document.
For this paper, the approach proposed for allowing Bert to process a long document is somewhat unexpected. The authors simply do not let Bert process a long document at all. Instead, they treat each sentence within the same document as an individual document. By doing this, they can avoid pass a long document to Bert model.
The first insight that the authors exploit is that only a few sentences in the documents are sufficient to represent the entire document (at least for a passage ranking task). This is somewhat surprising because we could end up losing a lot of information from the document. The way they compute the document score for the given query is to use the Bert to score all pair of (query, sentence), then pick the top 3 pairs with the highest scores, then the sum of these scores is the relevant score for this long document. This is a pretty simple idea and it works.
Another finding that the authors found has to do with the transferring. They found that Bert model is effective as transferring the knowledges from one domain to another. They found that by fine-tuning the Bert with Twitter ranking dataset, then fine-tuning one more time with the domain-specific task gives a significant boost in the performance. This demonstrates how well Bert can capture the common knowledge between two datasets.
Reference:

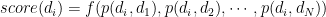 They tried different aggregation function
They tried different aggregation function  and shows that summing and binary function work quite well.
and shows that summing and binary function work quite well. 




 is an extra input to the network and we generate it from a Gaussian noise
is an extra input to the network and we generate it from a Gaussian noise 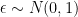 .
.
![E_{q(y|x)}[E_{q(z|x)}[\log P(x|z,y) - KL(q(z|x)||p(z))] - \log q(y|x)] =](https://s0.wp.com/latex.php?latex=E_%7Bq%28y%7Cx%29%7D%5BE_%7Bq%28z%7Cx%29%7D%5B%5Clog+P%28x%7Cz%2Cy%29+-+KL%28q%28z%7Cx%29%7C%7Cp%28z%29%29%5D+-+%5Clog+q%28y%7Cx%29%5D+%3D&bg=ffffff&fg=000&s=0&c=20201002)
![\sum_{y \in Y} q(y|x)[E_{q(z|x)}[\log P(x|z,y) - KL(q(z|x)||p(z))] - \log q(y|x)](https://s0.wp.com/latex.php?latex=%5Csum_%7By+%5Cin+Y%7D+q%28y%7Cx%29%5BE_%7Bq%28z%7Cx%29%7D%5B%5Clog+P%28x%7Cz%2Cy%29+-+KL%28q%28z%7Cx%29%7C%7Cp%28z%29%29%5D+-+%5Clog+q%28y%7Cx%29&bg=ffffff&fg=000&s=0&c=20201002)
![\sum_{y \in Y} q(y|x)[E_{q(z|x)}[\log P(x|z,y) - KL(q(z|x)||p(z))] - \sum_{y \in Y} q(y|x)\log q(y|x)](https://s0.wp.com/latex.php?latex=%5Csum_%7By+%5Cin+Y%7D+q%28y%7Cx%29%5BE_%7Bq%28z%7Cx%29%7D%5B%5Clog+P%28x%7Cz%2Cy%29+-+KL%28q%28z%7Cx%29%7C%7Cp%28z%29%29%5D+-+%5Csum_%7By+%5Cin+Y%7D+q%28y%7Cx%29%5Clog+q%28y%7Cx%29&bg=ffffff&fg=000&s=0&c=20201002)
 .
.
 is high, it means we need to use more bits to encode the event. The highest entropy is when
is high, it means we need to use more bits to encode the event. The highest entropy is when 






 and derive the ELBO:
and derive the ELBO:![\sum_{y \in Y} q(y|x)[E_{q(z|x)}[\log P(x|z,y) - KL(q(z|x)||p(z))] - \log q(y|x)]](https://s0.wp.com/latex.php?latex=%5Csum_%7By+%5Cin+Y%7D+q%28y%7Cx%29%5BE_%7Bq%28z%7Cx%29%7D%5B%5Clog+P%28x%7Cz%2Cy%29+-+KL%28q%28z%7Cx%29%7C%7Cp%28z%29%29%5D+-+%5Clog+q%28y%7Cx%29%5D&bg=ffffff&fg=000&s=0&c=20201002)









You must be logged in to post a comment.