Back in 2010, RNN is a good architecture for language models [3] due to its ability to remember the previous context. We will explore a few RNN architecture for learning document representation in this post.
Semi-supervised Sequence Learning [2] (NIPS 2014)
This model uses two RNN, the first one as an encoder, and later as a decoder.

Instead of learning to generate the output like in seq2seq model [1], this model learns to reconstruct the input. Hence, this model is a sequence autoencoder. LSTM is used in this paper. This unsupervised learning model is used for pretraining LSTM for different tasks such as sentiment analysis, text classification, and object classification.
A Hierarchical Neural Autoencoder for Paragraphs and Documents [4] (ACL 2015)
This model introduces a hierarchical LSTM to learn a document structure. The architecture has both encoder and decoder. The encoder processes a sequence of word tokens for each sentence. The final output from LSTM represents the input sentence. Then, the second LSTM layer will take a sequence of sentence vectors and output a document vector.
The decoder works in a backward fashion. It takes a document vector and feeds it to the LSTM to decode a sentence vector. Each sentence vector is then fed to another LSTM to decode each word in the sentence.
The author also introduces attention mechanism to put emphasis on particular sentences. The attention boosts the performance of the hierarchical model.

Generating Sentences from a Continuous Space [5]
This model combines RNNLM [3] with Variational autoencoder. The architecture is again composed of an encoder and decoder and attempts to reconstruct the given input. The additional stochastic layer converts an output from an encoder to mean and variance of the target Gaussian distribution. The document representation is sampled from this distribution. The decoder takes this representation and reconstructs word by word through another LSTM.

Training VAE under this architecture poses a challenge due to the component collapsing. The authors use KL annealing method by incrementally increases the weight of the KL loss over time. This modification helps the model to learn a much better representation.
Conclusion
There are a few more RNN architectures that learn document/sentence representation. The goal of learning the representation can be varied. If the goal is to generate a realistic text or dialogue then it is critical to retain syntactic accuracy as well as semantic information. However, if our goal is to obtain a global view of the given document, then we may bypass syntactic details but focus more on semantic meaning. These 3 models show how RNN architectures can be used to model for such tasks.
References:
[1] Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. “Sequence to sequence learning with neural networks.” Advances in neural information processing systems. 2014.
[2] Dai, Andrew M., and Quoc V. Le. “Semi-supervised sequence learning.” Advances in Neural Information Processing Systems. 2015.
[3] Mikolov, Tomas, et al. “Recurrent neural network based language model.” Interspeech. Vol. 2. 2010.
[4] Li, Jiwei, Minh-Thang Luong, and Dan Jurafsky. “A hierarchical neural autoencoder for paragraphs and documents.” arXiv preprint arXiv:1506.01057 (2015).
[5] Bowman, Samuel R., et al. “Generating sentences from a continuous space.” arXiv preprint arXiv:1511.06349 (2015).
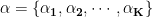 , a document with L tags (k=2, k=5) will have an alpha
, a document with L tags (k=2, k=5) will have an alpha  . Then the topic assignment will be constraint to only topic 2 and 5.
. Then the topic assignment will be constraint to only topic 2 and 5.
You must be logged in to post a comment.