This paper proposes an effective method for sampling negative examples. They claim that their method improves the effectiveness of the dense-based retrieval model.
Local in-batch negatives are not helpful for training the dense-based retrieval model
The authors argue that the local in-batch negative fails to sample the negative examples that are hardly distinguished from the positive example. The argument starts with the batch size tends to be much smaller than the corpus size. Moreover, the number of hard negative examples is even smaller; therefore, the chance that the in-batch negative sampling will pick these hard negatives is extremely low and close to zero.
The Negative Sampling method
The negative sampling method is surprisingly intuitive. The authors use the current retrieval model to build the ANN index offline then retrieve the list of items for each query in the mini-batch from the ANN index. Any item that is not part of the positive examples will be treated as a negative example.
The challenge with this approach is to build the ANN index and retrieve the items during the training. The index building process could take a large chunk of training time. The authors opt to build the new ANN index for every m epochs. Specifically, for every m epochs, the current model checkpoint will be used to create new item vectors and these vectors will be indexed.
My thoughts:
I felt this approach could make the model overfit to the train data. However, according to the MSMACRO leaderboard (https://microsoft.github.io/MSMARCO-Document-Ranking-Submissions/leaderboard/), many top 15 models utilize the ANCE learning. This concludes that ANCE learning is an effective method for sampling a hard negative example.
A neural retrieval model is quite different from a neural ranking model. The retrieval model has to distinguish relevant items out of million or even 100 million items at scale. In contrast, the neural ranking model is given a much smaller subset of items (e.g. 1000 to 2000 items); hence, it has a luxury to utilize a computational expensive transformer-based model.
The goal of training the retrieval model is always to teach model to roughly separate relevant items from a large pool of items. It is helpful if the model could see more irrelevant items during the training so that it can estimate the distribution of relevant and irrelevant items. The limitation that I always encounter while training the large retrieval model (e.g. transformer-based architecture) is the limited number of negative samplers due to the memory constraint on GPUs.
Typically, the training instance is a pair of query and item or a pair of query and a list of items both relevant (positive) and irrelevant (negative) items. If this list is too long, the mini-batch will be too big to fit into the GPU. This force the developer to cap the number of items per query which greatly reduces the number of negative items. The quick remedy for this is to use an in-batch negative sampling method. This approach samples negative items from all items within the mini-batches. This approach increases the diversity of the negative items somewhat. The enhanced method is to be smart about which item to sample. The hard-negative sampling strategy is used here. For example, an item with high cosine similarity with the input query but taken from a different query-item pair that could be a good negative sample.
I think we could do better than this. I have found two approaches that could be implemented and potentially improve the effectiveness of our retrieval models.
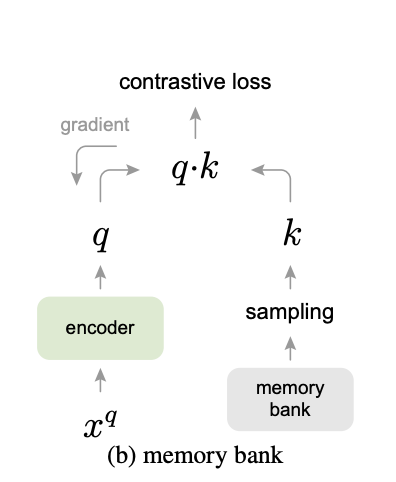
Memory Bank
The first approach is memory bank. This method is proposed by [1] for the unsupervised feature learning task in computer vision. The key idea is to incrementally build an item vector during the training and save the vector on CPU ( or GPU if that is possible ). This designated vector storage is referred as a memory bank. During the training, the model samples a pair of positive and negative items from the memory bank. This approach can avoid encoding a large number of items which could save some GPU memory.
Memory Bank
The original paper uses this approach to train a single encoder. Basically, during the training, the weights of the encoder is updated per query. To stabilize the gradient, the proximal regularization is proposed. The idea is to encourage the model to make a small change to the encoded vector by incurring a large penalty if the L2 distance between the previous vector and the current vector is too large.
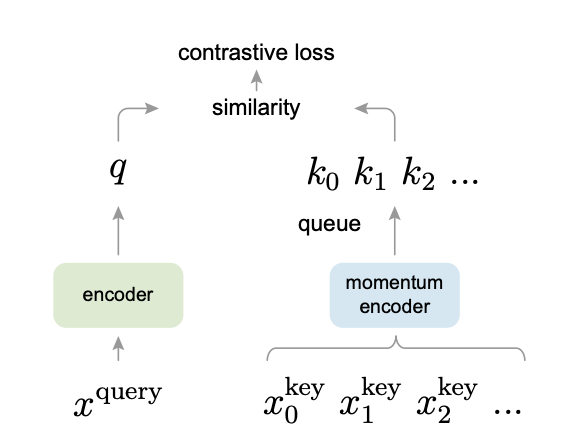
Momentum Constrast
In a memory bank method, one issue is that the encoder is learned slowly due to the proximity regularization. It would be nice to allow the encoder learns a bit faster. Another more serious issue is that the vectors in the memory bank could be inconsistent because the vectors must be pre-computed from the previous training step. The paper from FAIR [2] attempts to address to these issues.
Momentum Contrast
The main goal of this paper is to build a memory bank that are large and consistent with the training model. The authors proposed a queue-based dictionary by progressively inserts new vectors from the current mini-batches to the queue and discard the vectors from the oldest mini-batches.
However, with this approach, there is no direct way to update the weights of the item encoders. The authors proposes a method called momentum update. The weights of the item encoder is influenced by the weights of the query encoder. Specifically,
We denote as the weights of the item encoder. as the weight of the query encoder. m is a momentum parameter. The authors set m to 0.999.
In sum,
Increasing the size of negative samplers is an important task that allows the encoders to learn a rich set of negative items. Hence, we can potentially the effectiveness of the neural retrieval model.
To be honest, I am not sure which category for this post.
Back in August when I travelled to Maui with my family, I had nothing to do on the plane. I still remember my first impression with AI when I read about Minimax algorithm. The algorithm is intuitive and easy for me to understand why the AI can play the an optimal move on a 2-player board game.
To fulfill my early interest in AI, I code the minimax for Tic-Tac-Toe game. The result is so satisfying. I feel like I watch a baby bird learns how to fly. 🙂
In the e-commerce, the labels are usually impression, clicks, add to cart, and order. The ranking model is typically trained on these labeled data. It is possible to design multiple objective function using these labels.
One key observation is that these labels are strongly depended on one another. For instance, a merchandise item would not be purchased if it was never clicked. This work attempts to model these label relationship through the sequential models.
The model is trained to predict the clicks, impression, atc, etc. For each label, the hidden representation is created through the feed forward networks. Due to the sequential dependent between clicks, atc, impression. The hidden representation for clicks is a function of the impression; and same for ATC as well as the number of orders. The simple recurrent neural nets is used to learn these hidden representation.
The multi-objective functions are weighted by the learnable weight parameters. One modification to the objective function is to enforce the predicted impression to be greater the predicted clicks and so on.
In sum, for some instances of the multi-task learning problem, we can try to make each task to be correlated. This idea seems to be useful in the e-commerce application.
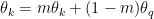
 as the weights of the item encoder.
as the weights of the item encoder. 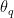 as the weight of the query encoder. m is a momentum parameter. The authors set m to 0.999.
as the weight of the query encoder. m is a momentum parameter. The authors set m to 0.999.
You must be logged in to post a comment.