I have been trying to implement Andrew Ng’s ICA but always get a numerical error. So I have found that computing a log determinant of a matrix can be tricky and leads to numerical error.
Another ICA’s algorithm is from Shireen Elhabian and Aly Farag. I found this algorithm is more numerical stable than the Andrew Ng’s method.
I have found the code that implements both methods and I reused the author’s code to perform blind source separation task on the toy data.
Here are the results:
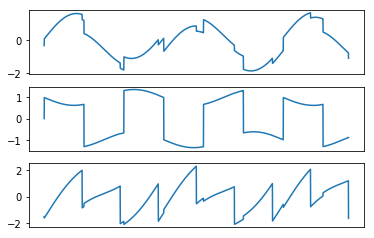
Original Signals

Mixed Signals (Observed Signals)

Recovered Signals using FastICA
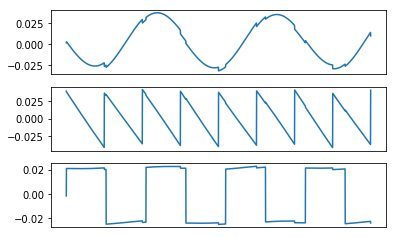
Recovered Signals using PCA
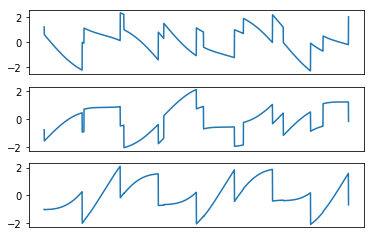
Recovered Signals using Andrew Ng’s method
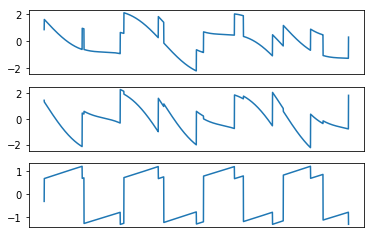
Recovered Signals using Shireen’s method
FastICA performs extremely well on the toy data. Andrew Ng’s method is very sensitive to the learning rate and does not perform well compared to Shireen’s method. Shireen’s method produces the better recovered signals, at least for this toy data.
Lesson Learned:
I attempted to use pyTorch to implement ICA and found very difficult to get a good result due to the numerical instability. The log-determinant term is troublesome and I have spent a few days trying to understand the insight of the determinant of a matrix. It is always a good idea to look into math to get a better insight.
I think one serious drawback with the change variable method is the need to compute the determinant of the weight matrix. I found that the author of RealNVP’s paper designs the neural network so that the weight matrix is a lower-triangular matrix in which the determinant is just a product of the diagonal entries.
ICA is a linear model so it won’t do well on the complex data. Finally, to train the model using gradient descent can be tricky since some maximum-likelihood models are prone to a numerical instability.
[code]

You must be logged in to post a comment.