The previous post, I trained the model on a grayscale image, today I will train the model on a color image from CIFAR10 and STL datasets. It is much more difficult to make it work.
DCGAN
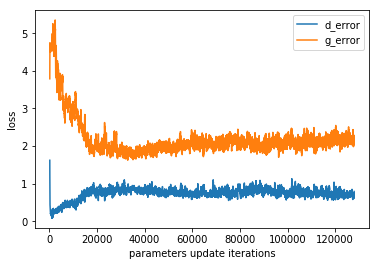
I just simply changed the model to take a color image by changing the number of input channels to 3 but got no luck. The model fails gracefully because the generator fools the discriminator with a garbage:

20 CIFAR images generated by the generator of DCGAN. The model cannot learn anything. Each row is the number of epochs starting from 10 (top), 50, 100, 150, and 200. Each column is a unique random vector sampled from a uniform distribution and used as the initial input to the generator.
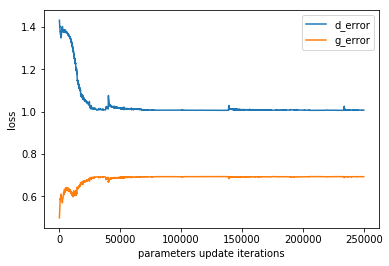
When we look at the loss, the generator performs better because the discriminator can’t distinguish anything.
After many trial-and-error, one change that works is to scale an image to 64 by 64 and normalize each color channel to have a center of 0.5 with a standard deviation of 0.5. I also use torchvision to plot an image which is very convenient than using matplotlib.
Here are generated CIFAR10 images from DCGAN:

The generated CIFAR10 images after 10 epochs

The generated CIFAR10 Images from the Generator after 150 epochs
The loss from the generator and discriminator look much better:
CVAE
CVAE has a similar issue as DCGAN. The architecture I used for MNIST does not work for CIFAR10 dataset. I use a similar architecture used in DCGAN for CVAE model. Here are the results (after the model is converged):
There are 10 classes, but I will just plot the generated images from the first 3 classes (airplane, automobile, and bird):

Generated airplane Image using CVAE

Generated automobile Image using CVAE

Generated bird Image using CVAE
Although the generated images show that CVAE learns *something* but it does not learn conditional probability 
Conclusion:
I have just entered the art (dark) side of the deep learning. Finding the right architecture is painful and can be frustrating. Training GANs requires a few tricks to make it work. For example, I have to use SDG to train the discriminator and use ADAM to train the generator. There is no formula for the right architecture and I hope one day we will understand deep neural nets better!
On the other hand, VAE does not generate a sharp image compared to GAN. There are many works that proposed an extension to VAE so it can generate a sharper image. That is something I will explore later as well.
Cheers!

You must be logged in to post a comment.