Limitation of Vanilla VAE
Variational autoencoder (VAE) is one of the simplest deep generative models. The implementation is almost similar to a standard autoencoder, it is fast to train, and generate reasonable results.
Although VAE may not sound as sexy as GANs or is not as powerful as an autoregressive model, this model has a probabilistic perspective which can be useful for model interpretation and extensions.
But a vanilla VAE is notorious for generating a blurry image:
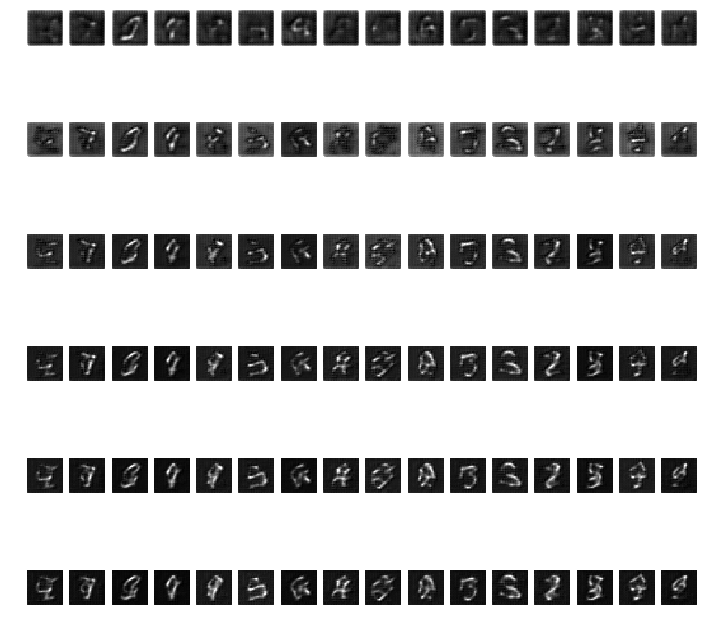
16 sample images from a Vanilla VAE. Each column is one unique image and each row is the epoch. Each row represents epoch iteration starting from epoch 0, 3, 6, 9, 12, and 15.
Even if the model has already converged, the image samples are not as clear as images generated by GANs. However, we can still recognize some digits.
However, sampling from VAE or any generative model is somewhat useless if we do not have the control of what we want. It would be nice if we can sample any digit we want.
Conditional VAE (First attempt)
The work from Diederik Kingma presents a conditional VAE [1] which combines an image label as part of the inference. Puting the math and derivation of the ELBO aside, the key change to the vanilla VAE’s architecture is to add a discriminator to classify the given MNIST digit and use this prediction as additional information to the decoder.
Ideally, if we tell the decoder that we want to generate a digit 1, the decoder should be able to generate the desired digit. Vanilla VAE does not have this information.
I extend VAE by simply adding a class vector to the decoder and hope that the decoder will learn to generate only digits from the given class.
Here is the result:

sampled images from the modified VAE whose the decoder takes both image latent vector and class vector. Each row represents one digit class, starting from digit 0 to digit 9. Each column represents one random vector. We use the same vectors but varies the class vector.
The result does not look good. All images in the first column look the same. The 9th column is the only column that each sample images are different.
KL Annealing
One technique to prevent VAE from being lazy and stop learning is to disable KL loss during the first few iterations and enable KL loss a bit later. This minor change helps the model to learn a good representation:

We can now see that the decoder can generate a correct digit. It shows that by just passing a class vector, the model can easily utilize this information.
The problem with fusing a class vector and latent vector?
The previous method concatenate vector of class vector and image latent vector before feeding to the decoder. This vector is transformed and reshape to a square matrix so that the deconvolutional layer is applicable. I found that fusing a class vector to the latent vector is a bit strange. The deconvolutional layer should expect a matrix that preserves the spatial relationship. E.g. The entries around the top right should be somewhat correlated. But the simple fusing method mentioned earlier does not seem to preserve this property. It would be interesting to see find out what other fusing strategies that can be more effective than just a vector concatenation.
References:
[1] D. Kingma, “Semi-supervised learning with Deep Generative Models” NIPS’14 https://arxiv.org/pdf/1406.5298.pdf

You must be logged in to post a comment.