My last post, my CGAN’s architecture does not work and when it is trained, its generator will learn nothing (complete mode collapsing issue). After a few days of research and read a few tips online, I’ve found the architecture for CGAN that works!
Before I describe the specific architecture for CGAN, here are the results:
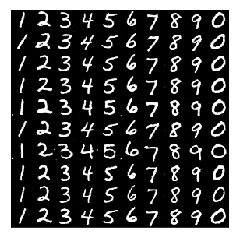
generated MNIST digits by CGAN. It is easy to interpret each row as a stroke width, stroke style.

generated fashion items by CGAN. It is harder to interpret each row.
The loss of discriminator and generator look much better:
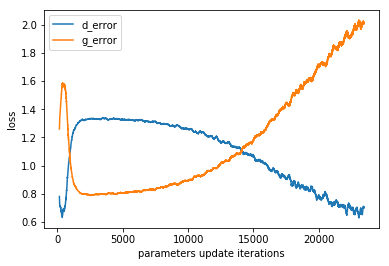
Loss on MNIST dataset
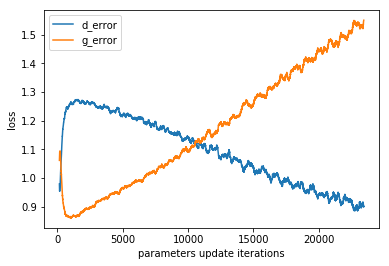
Loss on Fashion-MNIST dataset
The most important component of CGAN is the way we combine class label and actual image/latent vector as one input unit to the discriminator/generator. The choice of architecture either makes or breaks the model.
Generator
It takes two inputs: latent vector and class label.
- Latent vector is a random vector drawn from a normal distribution, mean at 0 with a unit variance.
- A class label is a one-hot vector.
- We concatenate these two vectors and use a few feedforward layers to merge them.
- Finally, we pass the new vector into deconvolutional layers.
Discriminator
It takes two inputs: generated image/real image and class label.
- Generated image or real image is a 2d matrix.
- a class label is converted to a 2d one-hot representation. This component was missing from my previous CGAN implementation. I will describe it a bit later.
- The generated/real image with 1 color channel + 10 channels from 2d one-hot representation.
2D one-hot representation
The idea is simple. For each class label, we represent it as 10 matrices ( or a matrix of size 10 by image width by image height ). For a class label i, the ith matrix is one matrix, the rest are zero.
This representation is simple and combines nicely with the actual 2d image. I will explore deeper into this choice of representations and how it might affect the discriminator.
References:
[1] https://arxiv.org/abs/1411.1784





You must be logged in to post a comment.