Word embedding has become a standard tool in many IR tasks. The popular tools such as Word2Vec[2] and GloVe [3] map each word to an embedding space where similar words are nearby. The similarity measurement is based on semantic or syntactic between words. Typically, similar words tend to stay in the same context. Thus, the objective functions exploit this assumption such as CBOW or skip-gram models. As a result, the models are very good at guessing another word given the context.
However, the authors believe that semantic and syntactic similarities are not an appropriate metric in IR tasks such as query expansion and classification. In the query expansion, we want to suggest an additional term that is relevant to the query but not necessary semantically or syntactically similar to. For instance, the given query is “indian american museum”, the Word2Vec will suggest words such as “united, states” because “united” and “states” are semantically similar to the word “american”. But these are not good term expansions. The relevent-based embedding will suggest the words that are relevant to the ‘whole’ query such as “heye, chumash, apa” which are more directly related to the query terms. Based on this idea, it motivates the authors to develop a relavance-based word embedding.
This paper proposes two models: Relevance Likelihood Maximization (RLM) and Relevance Posterior Estimation (RPE). The first model, RLM, is consists of two distributions:
– the relevance model distribution for the given query
where
. Basically, this distribution is a product of ‘how likely word w is relevant to all relevant documents in the top K documents’ and ‘how similar between query
– the similarity between embedded word w and query q.
. We normalized it so that the distribution will sum to a unity.
To interpret this model, we basically use the relevance model distribution as a weight to signify the similarity between a particular query and word. This weight is computed via a traditional PRF model. (see eq.3). The neural network will be constraint by this given weight and will be able to find an embedding vector that hopefully maximize the likelihood function.
The second model, RPE, uses a mixture model by assuming that there are two language models for the feedback sets: the relevance language model and noisy language model. The author opts to cast this assumption to a binary classification problem by predicting if the given w does come from the relevance distribution of the query q. In other words, RPE wants to estimate the following distribution:
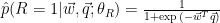
When a random variable R is one, it implies that word w in relevant to query q.
Two optimizations are necessary to train both RLM and RPE models. In RLM model, computing a normalization term is expensive, the author uses a hierarchical approximation of the softmax function [4] to speed up the training. Meanwhile, training RPE requires negative samples. The author chose the NCE [5] method.
The experimental results show that RLM model has a better performance than RPE models on a query expansion task. Both models outperform Word2Vec and GloVe due to its ability to put a high probability on words that are relevant to the entire query. However, RPE is better than RLM model on query classification task.
References:
[1] Zamani, Hamed, and W. Bruce Croft. “Relevance-based Word Embedding.” SIGIR’17
[2] Mikolov, Tomas, et al. “Distributed representations of words and phrases and their compositionality.” NIPS’13.
[3] Pennington, Jeffrey, Richard Socher, and Christopher D. Manning. “Glove: Global Vectors for Word Representation.” In EMNLP’14.
[4] Frederic Morin and Yoshua Bengio. 2005. Hierarchical Probabilistic Neural Network Language Model. In AISTATS’05.
[5] Michael U. Gutmann and Aapo Hyvarinen. 2012. Noise-contrastive Estimation of Unnormalized Statistical Models, with Applications to Natural Image Statistics. In Mach. Learn. Res. 2012.
